
2. 登录容器卡死
理论上系统中的关键路径,应该使用最可靠、最健壮的方案来支撑,但我接手的产品却不是这样,通常是做到能用的水平,这也就导致了今天要讨论了一个问题,关于 kubectl exec 这个 K8s 集群用户最常用的工具。
这个问题受到上层老板们关注时,我也正好也在现场支持,于是在驻场期内定位这个产品架构问题,开发了一个新组件替换原有的网络打通工具,彻底解决了这个存在已久的 bug。
客户现场的集群开始上量接入大量第三方软件提供商,接入过程中集群用户经常反馈无法通过 kubectl exec 登录容器,也无法通过网页控制台登录容器,另外在控制台上关于 Pod、Node 的监控数据也会经常缺失,kubectl logs 命令经常超时。
- 优先定位问题并提供临时解决方案,客户正在上量,不能阻塞使用
- 输出解决方案,争取合入下一个版本修改更新到现场
显然这个问题需要先确认 kubectl 执行 exec 与 logs 时会发生什么事情,从网上获取的资料看,当我们当执行 kubectl exec pod-name -it -- /bin/sh 登录容器时,请求会经过以下的链路:
flowchart LR
kubectl --> kube-apiserver
kube-apiserver --> kubelet
kubelet --> docker/containerd
docker/containerd --> container
执行 kubectl logs 时,请求链路也是类似的,但是在当前的容器产品中,情况有一些复杂:
- 控制台登录容器、查看/下载容器日志等操作,需要从管理网进入到用户网,再访问 kube-apiserver
- 容器集群的 Master 是托管在私有云底座集群上的,实际上就是三个 Pod,每个 Pod 中运行这控制面组件以及一些自研服务
- 受限于底座网络架构,运行 Master 的 Pod 中无法运行网络插件容器如 flannel、calico 等,当前是通过 apiserver-network-proxy 打通 Master 到集群网络的链路
我再次检查了代码,确认控制台上查看集群监控数据的请求也是经过 kube-apiserver 代理去访问集群内部的 Prometheus 获取的。
此时基本可以确认是 kube-apiserver 到集群网络的连通性问题,重新梳理后,我发现问题又扩大了,比如控制台集群详情页的绝大部分 api 接口(包括所有监控数据接口、部分列表接口),都可能因为访问监控数据失败导致超时。
简单来说,如果出现卡死,当用户需要查看 Pod 列表或者 Node 列表时,会因为访问不到 Prometheus 等待漫长的时间(因为需要等待请求超时)。
而我在和 Leader 同步完问题后,Leader 也给我反馈了一些新的情况,或者说是噩耗:
- 登录容器超时问题是已知问题,Leader 找到了产品原先的开发,确认存在问题,但他们当时无法解决就搁置了
- 其他正在上量的四个客户现场也出现一样的问题,登录容器卡死的 P1 问题单已经挂上夕会名单
在我感觉无比头大的时候,Leader 说出了那句经典台词:要不要重启下试试。那需要重启哪一个组件呢?
在加入 apiserver-network-proxy 后,原有的请求链路需要调整下,如下:
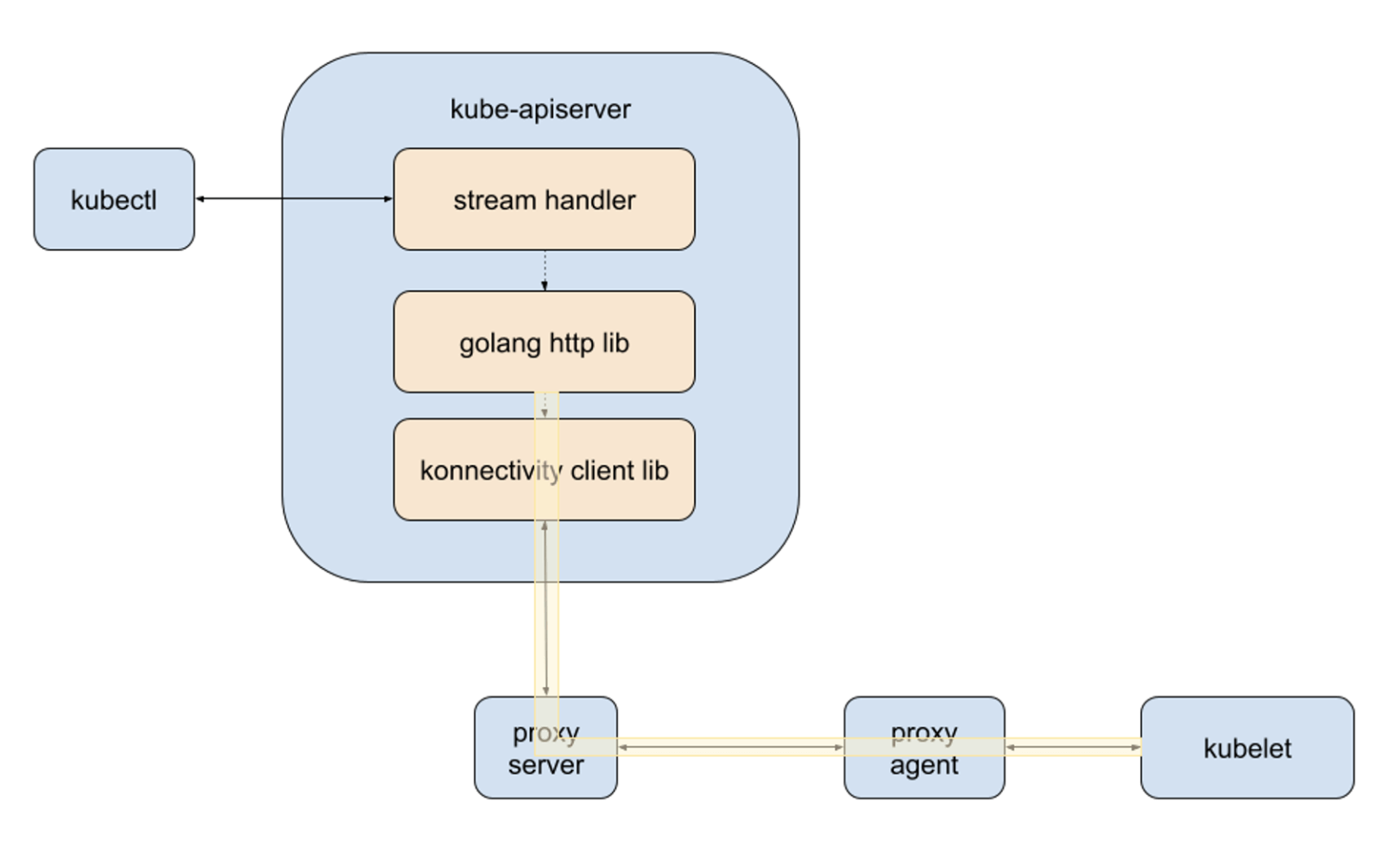
- kubect –> kube-apiserver: 使用 HTTP,支持streaming
- kube-apiserver –> proxy-server: 使用 gRPC,每次请求都通过本地Unix套接字新建一个连接
- proxy-server –> proxy-agent: 使用 gRPC,单一长连接,由agent主动发起连接,所有的kube-apiserver发起的请求都在该连接上复用
- proxy-agent –> kubelet:使用 TCP,每次新建连接
kube-apiserver 与集群内的节点和组件通信都需要经过 proxy-server + proxy-agent,在内部这两个组件打包成容器镜像后分别称为 kas-server 与 kas-agent。
其中 proxy-server 是作为一个容器嵌入在运行 Master 的 Pod 中,而 proxy-agent 则运行在节点上,集群初始化阶段会将三个 Master 的 IP 传递给三个 proxy-agent,这三个 proxy-agent 会使用 gRPC 连接到各自的 proxy-server,但架构问题导致 agent 无法同时连接三个 server,又埋下了一个坑。
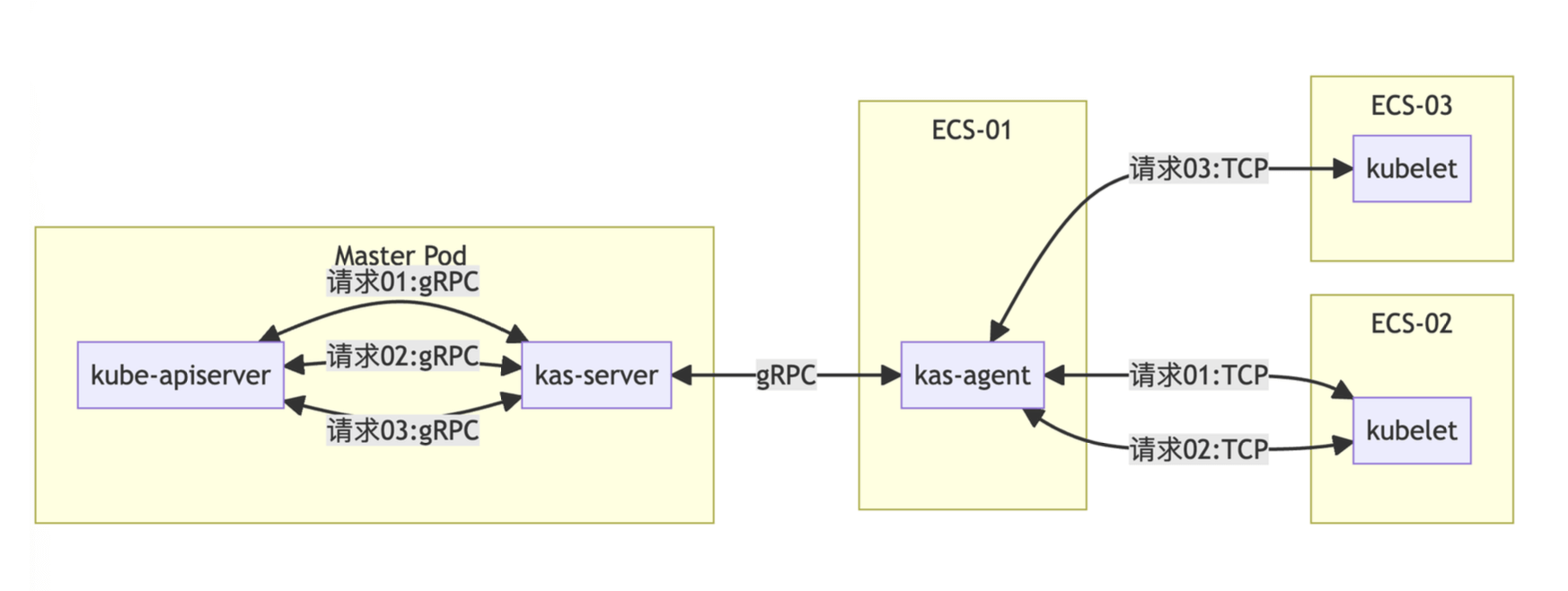
容器集群的一个关键路径由一个不太靠谱的 gRPC 连接在承载,遇上多人同时使用集群,特别是下载容器日志的操作,光是队头阻塞就可能导致超时。
既然确定问题出在 apiserver-network-proxy,我开始等待现场问题复现,验证重启 server 和 agent的效果,最后确定在卡死发生时,重启 server 可以释放连接恢复正常。于是速速写了一个跑在底座集群上的定时脚本,每隔 3 个小时扫描所有存量的容器集群,向运行 Master 的 Pod 中的 proxy-server 容器发送一个 kill 信号来触发重启。
临时方案让 Leader 暂时躲过了夕会上的被拷问,接下来就是分析代码了。
那什么是 apiserver-network-proxy?它是由 Kubernetes 社区开发的项目,旨在解决 Kubernetes API Server 与集群中其他组件之间的网络通信问题。该项目通过代理的方式增强了 API Server 的网络能力,使得 API Server 可以更灵活、安全地与集群内的节点和组件进行通信。有一个关键词 Konnectivity 与这个项目紧密关联:Set up Konnectivity service。
由于 Master 是托管在底座集群上,原先的开发人员为了解决 kube-apiserver 访问集群内部节点与组件的问题,不得不引入了 apiserver-network-proxy。
继续分析 proxy-server 和 proxy-agent 的代码,我发现 proxy-server 代码中,只有一个 goroutine 从 proxy-agent 的 gRPC 连接中读取数据,再根据请求 ID 分发到所有来自 kube-apiserver 的 gRPC 连接((ID 由 proxy-agent 生成,又是一个坑))。


proxy-server 卡住时,是阻塞在 frontend.send 函数上,即 proxy-agent → kube-apiserver 方向的传输阻塞,原因是kube-apiserver中断请求,典型的场景是执行kubectl logs中途按下ctrl+c,按下按键时会发生什么?
- kubectl 关闭请求,停止读取响应
- kube-apiserver 停止传输数据,向 proxy-server 发送一个 CLOSE_REQ 请求,并等待 CLOSE_RSP 响应
- proxy-server 转发 CLOSE_REQ 到 proxy-agent
- proxy-agent 收到请求,关闭和 kubelet 之间的连接,然后返回一个 CLOSE_RSP 给 proxy-server
- proxy-server 收到请求,将 CLOSE_RSP 转发给 kube-apiserver
- kube-apiserver收到请求,关闭 gRPC 连接
但有一种情况,比如使用 kubectl logs 获取大量日志时:
- kube-apiserver 发出的 CLOSE_REQ 并关闭了向 kubectl 传输数据的通道
- 在 CLOSE_REQ 传输到 proxy-agent之前,kubelet 还是往回大量传输数据,由于 kube-apiserver 读取 gRPC 写入 chan 阻塞,导致 proxy-server → kube-apiserver 之间数据传输阻塞
- proxy-agent 处理完连接关闭,CLOSE_RSP 到达 proxy-server 后,阻塞在 frontend.send 函数
- kube-apiserver 与 proxy-server 之间的 gRPC 连接无法关闭
相当于在一个 range 循环中往多个 chan 写数据,当其中一个 chan 阻塞时,当前 goroutine 被挂起。
我检查了运行 Master 的 Pod,存在大量未关闭的本地连接:
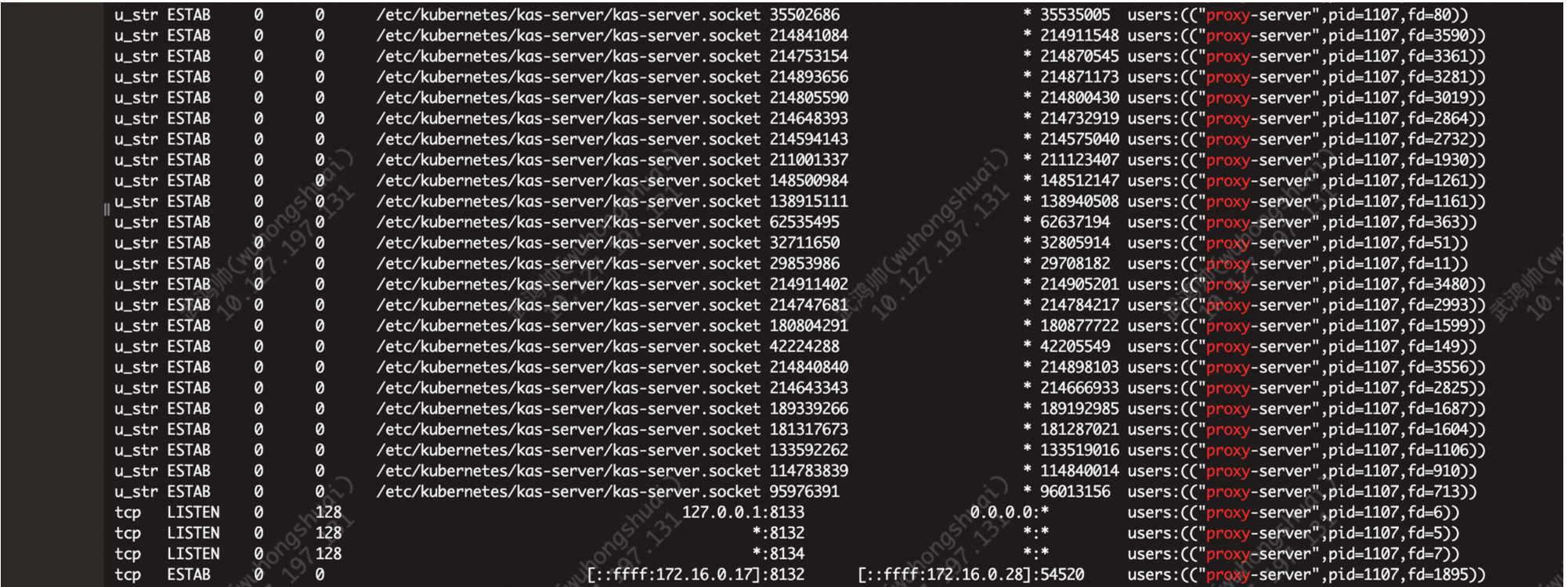
此时从 kube-apiserver 发起的新请求发送到 proxy-agent 后没有收到响应,proxy-server的日志中也没有 DIAL_RSP:
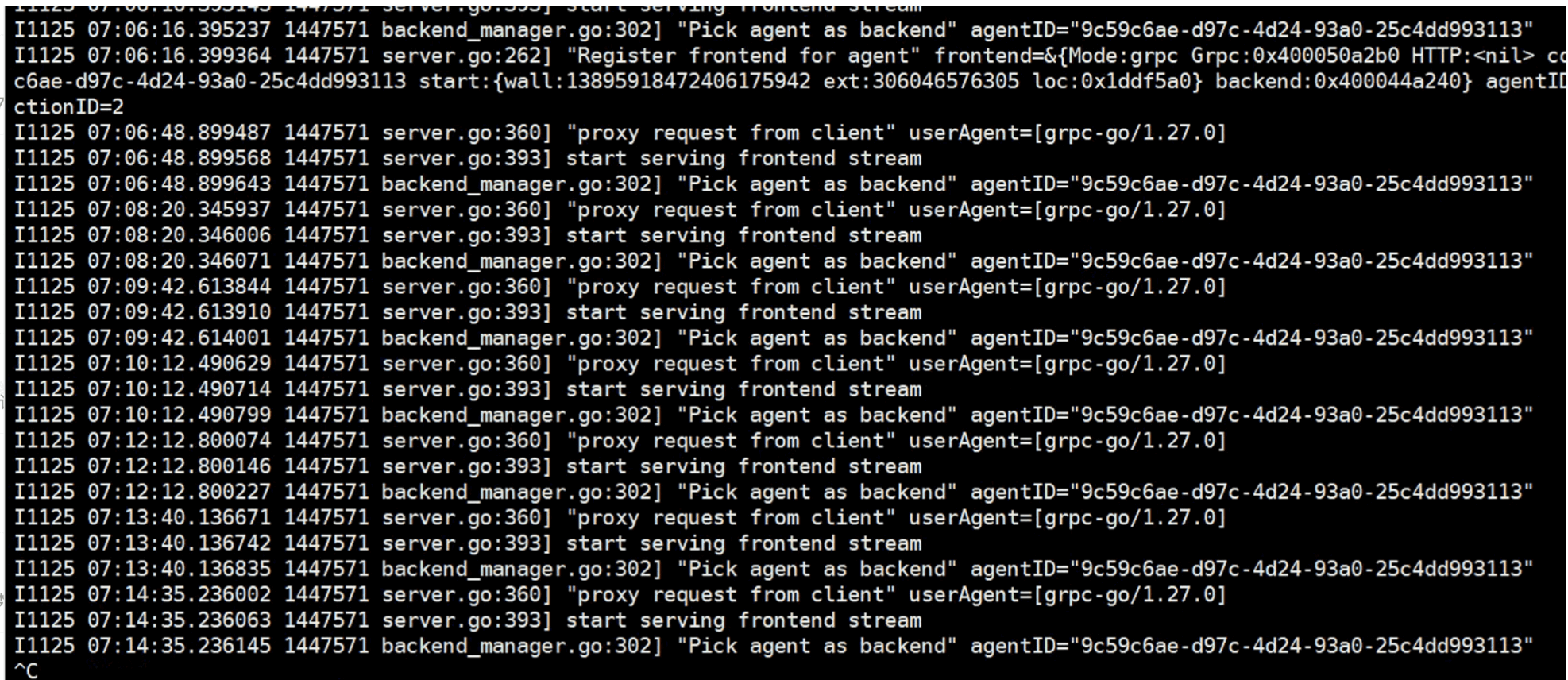
该如何修复问题呢?我仔细翻了一遍 apiserver-network-proxy 的 PR 列表后,终于发现了一个解决办法:在 kube-apiserver 侧增加一个超时时间,这样遭遇写入阻塞时,可以主动关闭 gRPC 连接,进而让 proxy-server 的 frontend.send 报错,让循环可以继续运行下去。
为了避免 P1 问题单一直挂载夕会上,Leader 拍板先根据 PR 输出一个修改方案合入版本发布,再降低定时重启脚本运行间隔,大概可以解决 80% 的问题,结果也如他所料,只是功劳主要还是在重启脚本。
存量的集群数量未知,至少超过 100 个,而更新 kube-apiserver 涉及重启 Master,需要走变更单,再回顾下之前的排查历史,无论是 kube-apiserver、proxy-server 还是 proxy-agent,都存在一些不易修改却又让人难受的 bug,我决定开发一个 apiserver-network-proxy 的代替品。
既然 gRPC 链路存在问题,那就使用 HTTPConnect 替代,这样原先需要 agent 主动发起连接建立隧道的操作就改成由 server 主动发起连接,每次新建连接,用完就释放,也就不存在队头阻塞的问题。
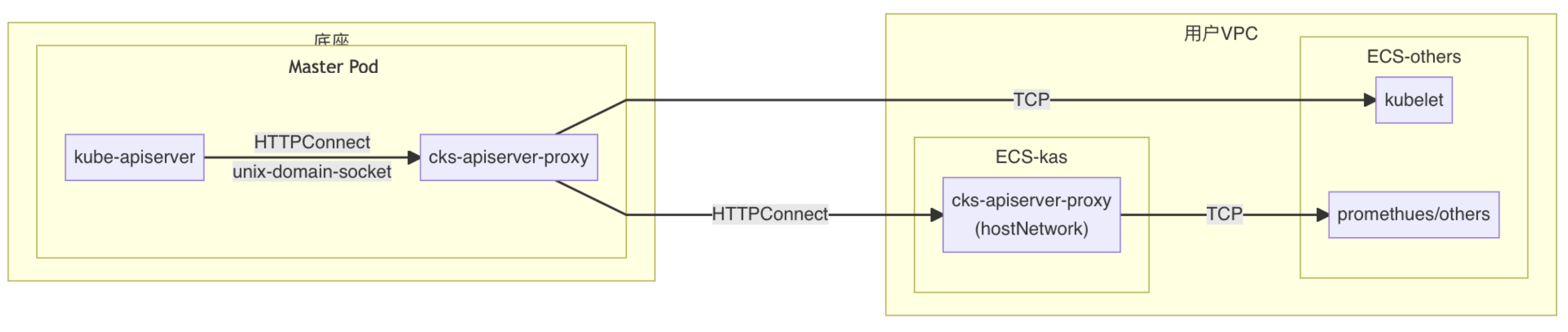
- 新组件部署方式与原先相同,每个控制面的 Pod 中有一个 server 模式的 cks-apiserver-proxy,节点上使用 statefulset 部署三个 agent 模式的 cks-apiserver-proxy
- 每个 agent 定时向 server 注册自己的 IP,server 则定时检查所有注册的 agent 的健康状态,server 与 agent 之间是多对多的关系
- server 模式下 cks-apiserver-proxy 会根据 HTTPConnect 握手时的 host 进行分流 a. 直连请求 (exec、logs,host属于 VPC 的 CIDR 内的 IP,端口为 10250)不走下一级代理,直接转发 b. 代理请求 (直连请求以外的,如 kubectl cp、kubectl top、网页查看监控数据等任何访问 ECS 上 Pod 的请求)走下一级代理,通过 agent 转发
- agent 模式下的 cks-apiserver-proxy 不执行分流,直接转发
我大概使用了两周的时候,完成了设计、开发、测试与合入版本,使用新版本的私有云创建出的容器集群再也不会有卡死问题了。
- 输出了临时方案,在所有存量集群的底座上部署了重启脚本缓存卡死问题
- 合入 K8s 主线修复方案到,更新 kube-apiserver 到新版本缓存存量集群问题,但碍于 apiserver-network-proxy的 bug,仍旧有可能出现卡死
- 输出了 apiserver-network-proxy 代替品,合入新版本,彻底解决访问集群内部节点或组件可能卡死的问题
我输出的三个方案只有第一个普遍实施,剩下的无论是更新 kube-apiserver 镜像,还是修改 Master 的 Pod 的配置,都因为需要走繁杂的变更操作阻塞。
私有云的软件版本就像手机的 APP,一旦发布出去了就难以控制,对于已经运行稳定的环境,无论是客户还是驻场同事,都不希望产生任何新的修改以免惹出麻烦。
这导致我在输出解决方案后,又不得不编写了许多文档给驻场同事应对存量集群故障问题。
如果我也不熟悉代理协议的话,可能就无法开发 apiserver-network-proxy 的代替品,使用 apiserver-network-proxy 应该是当时开发人员能想到的最佳方案,无需开发、直接部署。
可惜测试不够充分,从我处理现网问题的频率看,一旦重度使用容器集群,就容易发生卡死,除了 apiserver-network-proxy 外,我还排查出几个管控服务的 bug,例如控制台登录容器闪退(goroutine 异常退出)、控制台下载容器日志异常(JAVA 服务全量打印 Body 导致堆内存溢出)。
而我的重启脚本也重蹈覆辙,变成了一个固定配置,一些客户现场的驻场同事轮换后,就会给我提问题:为什么 Master 的 Pod 存在频繁的重启……