
1. 推送镜像到Harbor超时
在我入职前司一周不到还在探索代码屎山时,Leader 突然下发了一个任务,在有余力时协助 DevOps 团队解决推送镜像超时问题。
初步了解下来,DevOps 团队使用的镜像仓库是已离职的容器产品同事搭建的,就是一个 Harbor,但该镜像仓库中存储着整个公司的所有容器镜像,24 小时都有不间断的的推送镜像和拉取镜像动作。
前司重度使用 K8s,最开始所有人都归属于数据库团队,而经过重组后,却没有一个大的容器部门统管涉及容器技术的产品,底座 K8s 分配到了运营运维部门,DevOps 划为独立部门,我所在的容器产品(容器集群 + 容器镜像仓库)则归属于计算部门,可以是是各自玩各自的。
我主要负责容器集群的维护,还没太多 Harbor 的踩坑经验,但经过这一次的性能优化,基本摸清了 Harbor 的设计理念与架构,它真是一个十分优秀的开源项目。
公司内部部署了一个 DevOps 团队的 CICD 产品作为公共服务,工作流最后一步是推送镜像,但最近经常出现问题:
- 推送镜像缓慢,超时时间设置为1000s仍然无法完成
- 推送镜像时偶尔出现过500错误,即服务器内部错误
我初步调查了一下环境还发现了一些其他问题:
- 在 Harbor 网页控制台中,访问项目的仓库镜像列表访问十分缓慢
- 使用 Helm 拉取 Chart 偶发异常
当前最严重的问题是推送镜像超时,私有云的版本发布需要构建镜像、拉取、打包镜像,而且平时开发人员也都需要通过 CICD 产品在线构建容器镜像,然后推送到测试环境验证。
- 最优先任务是梳理镜像推送流程,定位故障出现位置,解决镜像推送超时的问题
- 逐步解决其他不影响版本发布的问题
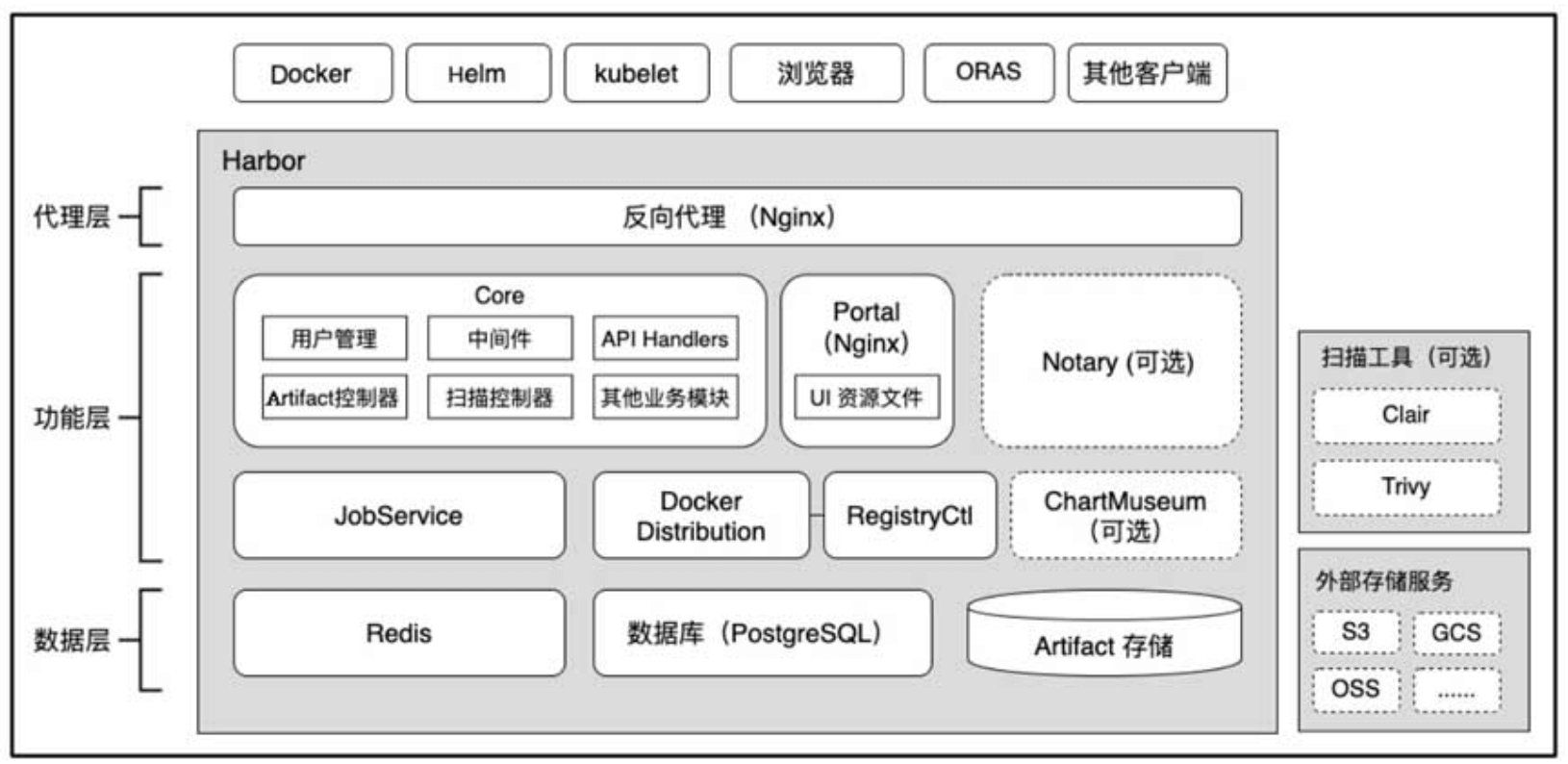
上面是 Habor 的架构,DevOps 团队的 Harbor 部署在一个物理机组成的集群上,没有部署文档或者 wiki,我只有访问集群 master 的权限和登录 master 节点的凭证,以及 Harbor 的管理员账号密码,初步了解下来有以下情况:
- 该 Harbor 实例使用 helm 部署,chart 版本为 harbor-1.6.0,App Version 为 2.2,主线最新版本为:harbor-1.9.3,App VERSION 2.5
- 该 Harbor 实例的几个组件除 redis 与 portal 的 Pod 外,其他组件的 Pod 都存在多次重启,检查 Pod 未发现 OOM 记录,基本都是 liveness 检查失败引起的重启,重启次数已经达到数千次
- postgres 是使用本地盘的单实例,内存占用 12G,持久化存储占用 78G,高峰期时,CPU 占用最大达到 33C
- redis 也是使用本地盘的单实例,内存占用 50G,持久化占用 40G,触发 checkout 时会跑满单核
- 在 Harbor 网页控制台上,选择一个项目进入后,访问镜像仓库列表十分缓慢,很容易出现超时
- 从控制台的数据统计,该 Harbor 实例目前存储了接近 300 万个镜像,占用的存储空间约 28TB(取大于 100GB 的项目计算)
- 集群的控制面服务也存在极高的重启次数,三个 master 上的 kube-apiserver 重启次数接近 1 千次(Pod 已创建 234 天),可能与 postgres 和 redis 运行在 master 上挤占资源有关
- Harbor 使用的 S3 存储由存储部门维护,是一个独立的浪潮存储集群
另外了解到以前出现过许多次类似问题,已经做过以下调整:
- 移除 nginx 组件,在 harbor 外新建了一个 ingress,将外来的请求直接分发到 core、chatmuseum、registry
- 该 ingress 的默认超时时间从 600 秒 调整到了 1000 秒
- core、postgres、registry 等组件 Pod 规格已经设置为不受限
总得来说之前处理问题的同学只是缓解了问题,随着使用量突增,已经无法简单通过垂直扩容减少故障发生频率。
由于这个 Harbor 牵扯的人员太多,我目前只能做一些只读操作,在确保不影响使用的情况下继续排查,同时研究 Harbor 的代码。
另外 DevOps 团队有一个问题反馈群,会在群里支持一些使用问题以及响应故障,我在群里潜水一段时间后,将模糊的问题细化了一下:
用户反馈的推送镜像失败其实分为四种:
- 404 错误:Harbor 组件正常未发生重启,但是 kube-apiserver 重启了,DevOps 团队的集群使用 Pod 在集群中构建镜像,遇到 404 错误时,连后续构建任务也无法启动,说明是 kube-apiserver 重启导致 ingress-controller 获取路由异常,直接抛出 404错误,需要从集群层面解决,目前 DevOps 团队的集群显然存在规划问题,让 master 承受了过大压力,一旦 kube-apiserver 崩溃重启,就引发一连串问题
- 5xx 错误:Harbor 组件发生重启,core 或者 postgres 服务异常,从日志看是健康检查失败,需要分析 helm 部署使用的 yaml 模板以及组件对应的健康检查接口
- 应用层错误:Harbor 组件未发生重启,core 服务直接抛出的错误,从日志看是访问 S3 存储异常,只能交给存储的 SRE 解决,当前使用 S3 存储没有健康检查与监控
- 超时错误:用户完成了镜像构建,但一直阻塞在推送镜像这个步骤直至超时,需要分析 Docker 推送镜像的具体实现
整理了资料后又和 Leader 沟通了一下,先着手优化 postgres 并添加组件的指标监控。
我与 DevOps 团队沟通后,,先在低峰期修改了 postgres 开启慢查询日志,同时拿到了集群中的一个公共 Prometheus 和 Grafana 访问权限,确认存在 Harbor 的 metrics。
累积了一段时间数据后,又有了一些结论:
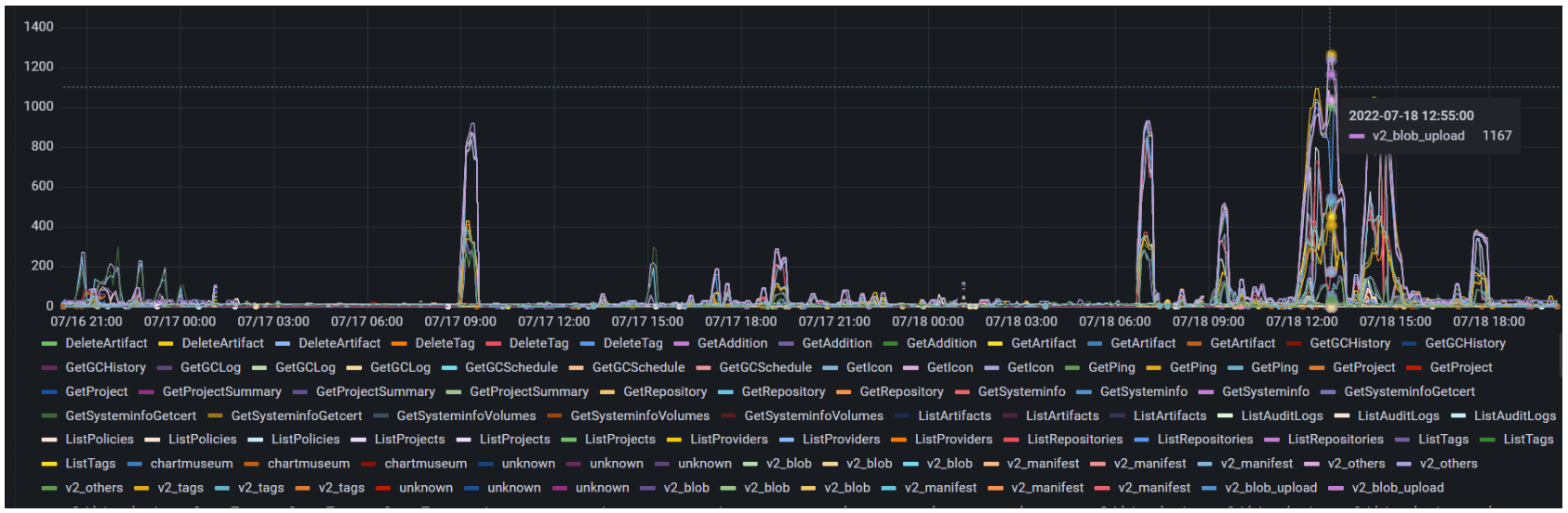
- 上传镜像的过程包含上传 blob、上传 manifest
- 从 grafana 记录的日志看,v2_blob_upload(PUT > PATCH > POST)、v2_blob、v2_manifest 等接口存在超长执行时间,高达 1000s 及以上,与推送镜像超时的现象匹配
- 慢查询日志显示读取 quota 表的执行时长存在数十秒以上的执行时间,代码逻辑里会使用主动加锁
- 第二项里的接口使用中间件间接执行 quota 相关查询
慢查询日志出来后,根据项目 ID 整理了一些数据。
取一小时数据库日志(1659次慢查询),分析锁定quota表相关的仓库:

从数据库取镜像仓库大于50的项目:
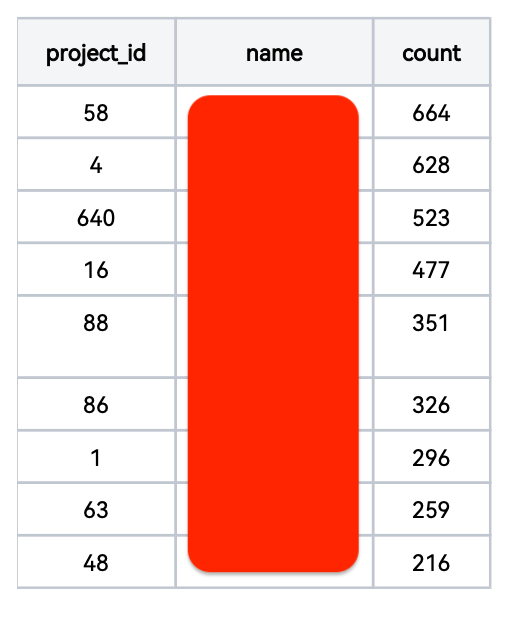
似乎仓库数量越多的项目越容易触发慢查询。
根据 Grafana 异常数据查询的 Harbor 接口也有了线索。
异常接口分析
- v2_blob_upload: 执行时间上,PUT > PATCH > POST
- v2_blob
- v2_manifest
调用到 quota 的代码目录为 src/controller/quota
主要有以下关键操作:
- Request调用成功: reserveResources -> Refresh
- Request调用失败:reserveResources -> unreserveResources
- reserveResources -> GetByRefForUpdate
- unreserveResources -> GetByRefForUpdate
- Refresh -> GetByRefForUpdate
- Update -> GetByRefForUpdate
而 quota 本身关联的代码目录为:src/server/middleware/quota
主要有以下关键操作:
- RequestMiddleware -> IsEnabled -> common.QuotaPerProjectEnable
- RefreshMiddleware -> IsEnabled -> common.QuotaPerProjectEnable
代码目录 src/common 中有读取环境变量控制全局 quota 的地方:QuotaPerProjectEnable -> QUOTA_PER_PROJECT_ENABLE
QUOTA_PER_PROJECT_ENABLE 默认为true,若关闭则产生以下影响:
- 请求接口中不再操作 quota,不触发 quota 表相关的 CRUD,垃圾回收结束时不再刷新quota
- 对用户来说: 项目定额功能 (限制存储占用大小) 失效,其余功能无影响
理论上开启或者关闭 quota 功能需要重启服务,但是我通过研究代码发现了一个内部接口: /api/internal/switchquota,调用接口即可开关 quota。
结论已经比较明显,推送镜像需要检查与更新 quota,这里的加解锁动作导致推送超时,但为何累积了这么多镜像?Harbor 本身的 GC 功能没有开启吗?
我继续测试了在控制台主动触发 GC,结论是确实没用,原因如下:
- GC使用单个goroutine执行标记和清扫,全由于需要整理在用的artifact和blob,需要对多个表执行全表扫描,因此速度非常缓慢
- GC在控制台目前只有触发接口,其他接口如获取任务状态、停止任务等需要直接调用jobservice的接口,难以操作
- GC过程缺少监控手段,无法检查GC进度
GC 时还有两个选项:
- 允许回收无 tag 的 artifacts: 是否需要扫描 artifact 表(高耗时操作),通过扫描 artifact 表生成需要回收的项目插入 artifac_trash 表
- 模拟运行: 是否需要真正的删除操作,会调用 registry 接口执行删除
临时应对策略:
- 仅执行标记: 允许回收无 tag 的 artifact(true) + 模拟运行(true)
- 仅执行回收: 允许回收无 tag 的 artifact(false) + 模拟运行(false)
继续测试了上述两个操作,实际无效,总是会超时失败,GC 速度无法跟上镜像数量增长速度,导致后端的 S3 存储数据量持续增长。
另外健康检查导致的 Pod 重启问题也有了结论:core 组件数据库连接数有过调整,导致三个 core 副本的总连接数超过了 postgres 预设的最大连接数,高峰期时 postgres 的 Pod 的健康检查由于无法连接数据库,触发 Pod 重启,postgres 数据库重启期间 core 服务的健康检查也失败了,导致 core 一并重启。
同一个项目下的多个镜像仓库并发构建时,在推送镜像阶段,会因为接口调用中执行的行级锁互相等待,请求耗时最多达到1000s以上,如下是core的请求时长记录
关闭项目Quota的两个办法:
- 修改配置字典(需重启): 修改 core 服务 configmap,添加一行QUOTA_PER_PROJECT_ENABLE: “false”,然后重启 core
- 调用接口(免重启): 进入 每个 core 服务所在容器内,调用内部API
curl -X PUT -H 认证信息 -d '{"Enable": false}' http://127.0.0.1:8000/api/internal/switchquota
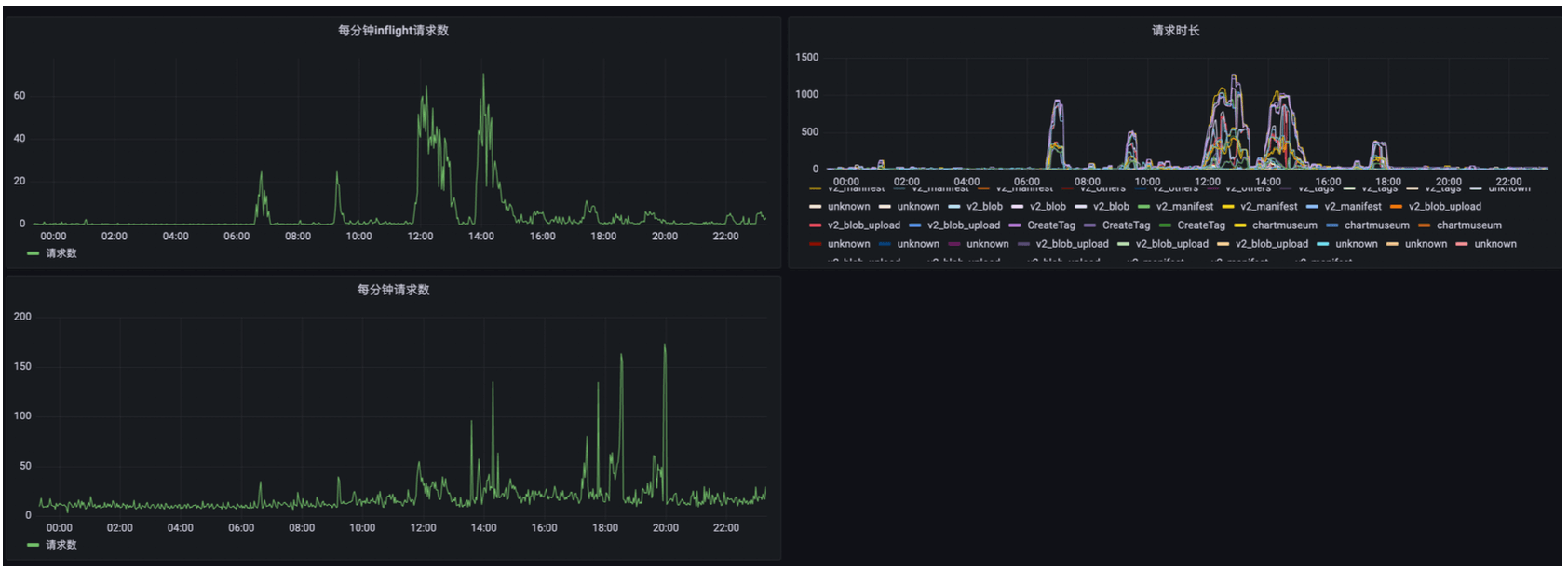
优化后 (2022-07-18 18:00:00完成调整),可看到请求数增加时,inflight请求反而下降了,说明请求被快速处理了,请求时长从大部分 1000s 左右下降到 40~60s
- 修改 core 服务的数据库连接池 MAX 与 IDLE,让 MAX 等于 IDLE(1000),且总数量不超过 postgres 数据库连接数(5000)
- 优化 postgres 数据库配置,调整最大连接数、缓存、工作内存、WAL日志大小
调整后未再反馈出现过 5xx 错误。
GC 问题无解,当前 Harbor 的垃圾回收策略无法应对大规模场景,最简单的办法是使用两个 Harbor:一个用于定期全量清空,专用于 CICD,另一个关闭 GC,用于归档。
这个建议在我最后离职时,DevOps 团队才开还着手实施。
- Redis 与 Postgres需要做高可用,但目前无法实施,为了减少 postgres 压力,我关闭了审查服务,清理掉无用数据后,postgres 占用的存储空间从 78G 下降到 10G 左右,以便后续迁移数据库
- Harbor 控制台访问镜像仓库列表缓慢的问题无解,就是数据太多了,分页需要时间
- 拉取 Chart 缓慢问题并不存在,只有极少请求耗时数秒,大部分都在毫秒级
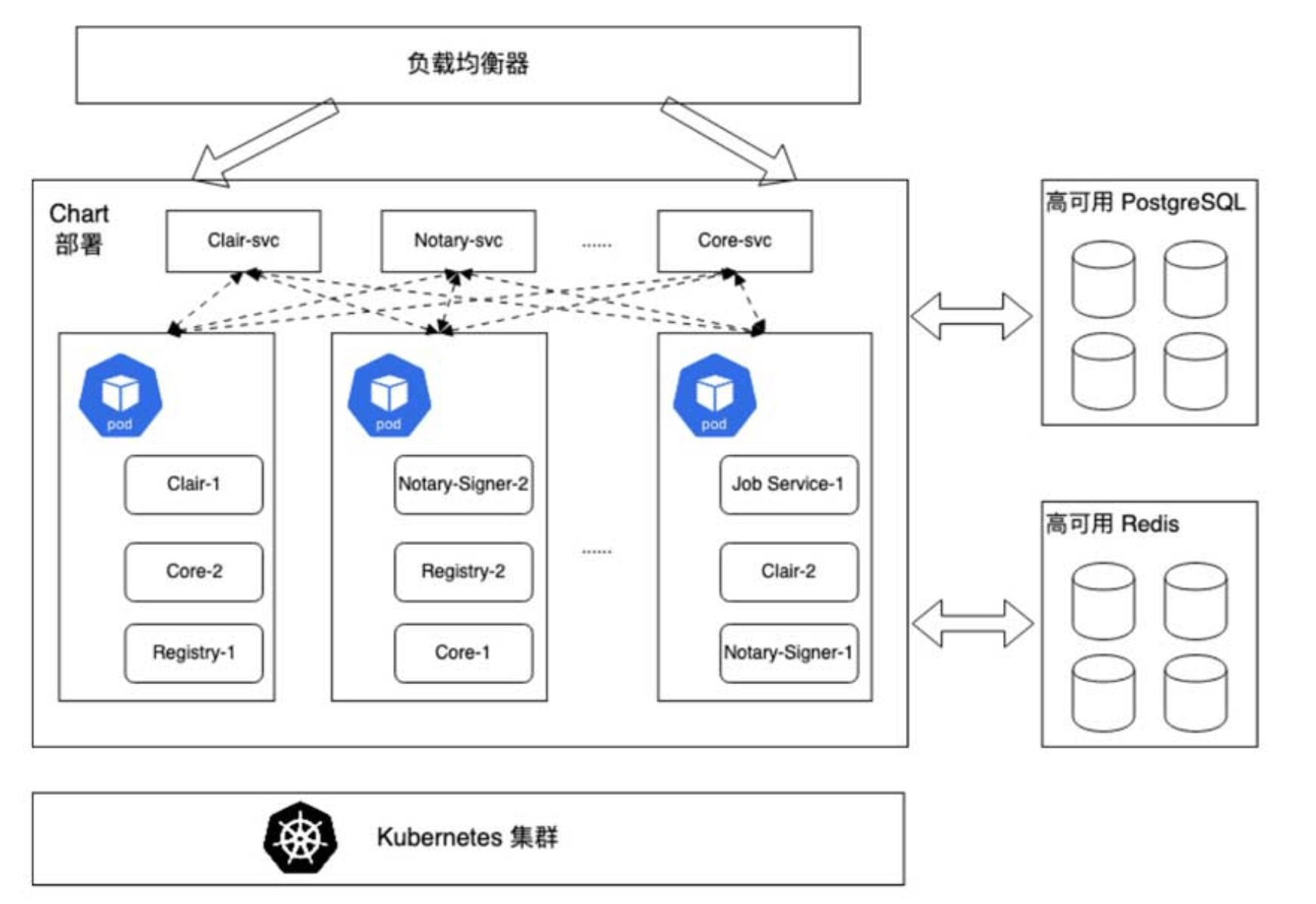
Harbor 的大部分组件都是无状态组件,它的高可用其实就是 postgres、redis 和 S3 的高可用。
jobservice中负责执行各种异步任务,包括垃圾回收。
获取状态
curl http://10.232.199.21/api/v1/stats | python2 -mjson.tool
curl -X GET -H 'Authorization: Harbor-Secret xxxxxxxxx' http://10.232.199.21/api/v1/jobs?page_number=2&page_size=100
获取任务状态
curl -X GET -H 'Authorization: Harbor-Secret xxxxxxxxx' http://10.232.199.21/api/v1/jobs/2f8b77c03a7cf47b9df110fa | python2 -mjson.tool
停止任务
curl -X POST -H 'Authorization: Harbor-Secret xxxxxxxxx' -d '{"action": "stop"}' http://10.232.199.21/api/v1/jobs/2f8b77c03a7cf47b9df110fa | python2 -mjson.tool